UNLP / FBA / DAA
Sonido I
Apuntes De Cátedra
Titular: Germán Suracce
JTP: Jorge Villapol
Ayudantes:
Marcos Scarcella
Nicolás Mazzola
Juan Molteni
Hernán Biasotti
Introducción:
Una de las necesidades primordiales cuando pensamos en el sonido, es la de comprenderlo mas allá de sus aspectos físicos, de sus cualidades mensurables y de sus propiedades en tanto que objeto. La comunicación audiovisual es un todo complejo, que abarca distintas áreas del saber tanto artístico como técnico.
La comunicación audiovisual es algo bastante más complicado que la pura intuición aplicada al manejo de la tecnología de las telecomunicaciones. La comunicación audiovisual es la técnica de engaño más compleja, más extraordinaria y más verosímil que se ha conseguido a lo largo de la historia de la humanidad. Su lenguaje trabaja con la propia esencia perceptiva de la realidad, capturando las informaciones sensoriales que emanan de los objetos, para componer con ellas narraciones que nos hacen oír y ver cosas que en ese momento y en ese lugar no existen, o que quizá no han existido ni existirán jamás, pero que percibimos como si fuesen la realidad misma.
Ante esta problemática, la inherente al estudio del lenguaje audiovisual (o el estudio de los lenguajes subyacentes que conforman el todo audiovisual), es necesario dar algunos pasos firmes en la comprensión científica de los mecanismos que estructuran ese fenómeno de alucinación consciente que sufre el ser humano cuando oye y ve sonidos e imágenes artificiales. Esto responde a la clara convicción de que el estudio no debe quedar centrado solamente en la tecnología que apoya la producción audiovisual. Se debe articular la psicología de la percepción, la física acústica y la narrativa audiovisual procurando que actúen como un todo unívoco, capaz de proporcionar respuestas a aquellos que quieren comprender como funciona la interpretación del mundo desde el sonido.
La formación en el campo audiovisual atraviesa un momento de indudable protagonismo en la actualidad.
Los medios de comunicación, la televisión, el cine, el ciberespacio, se han convertido en mecanismos de filiación social y cultural en permanente proceso de legitimación y, en tanto que ámbito de estudio, protagonizan el objeto de análisis e investigación de diferentes disciplinas académicas.
Llevar a cabo realizaciones audiovisuales e investigar en el vasto universo audiovisual nos hace partícipes de un proceso de continuas transformaciones a la vez que instaura la posibilidad de representar la realidad desde este particular lugar del saber y de la praxis.
Los saberes vinculados a estas prácticas devienen de dos espectros de formación habitualmente escindidos en las currículas universitarias en la actualidad: las artes, las humanidades, por un lado, y la comunicación y las ciencias sociales por el otro. Sin embargo, es necesario considerar el lenguaje y la producción audiovisual como un campo específico de formación y producción que articula de manera indisoluble los saberes y las capacidades del creativo, del artista, del realizador, con los cometidos propios del comunicador audiovisual, que hace uso de los soportes y géneros audiovisuales para la puesta en discurso de una idea, un saber, una inquietud, un mandato, un deseo.
El cine, la televisión, los sitios web, los cortometrajes de divulgación científica, didáctica o institucionales, devienen del dominio de un arte y de una concepción artística de dichos fenómenos al tiempo que se constituyen de manera ontológica en discursos que “dicen”, que comunican a los sujetos al tiempo que marcan un momento y hablan de una época, constituyéndose en verdaderos agentes de transmisión cultural y social.
Y en este sentido, las condiciones de producción de estos discursos determinan su innegable relación con los contextos políticos, económicos y sociales que los circunscriben.
Frecuentemente la información que se recibe en cuanto a los procesos que intervienen en la conformación de la banda de sonido de un audiovisual de cualquier tipo es escasa o nula, donde generalmente esta se asocia a una simple sucesión de libertades técnico-estéticas de un alto nivel de complejidad que involucra el distinto uso de herramientas tanto al momento de la producción como de la postproducción y se pierde de vista el valor implicitito del sonido como portador de sentido y como parte de una de las dos dimensiones (visual y sonora) constructoras del relato.
Nuestro propósito será dar las herramientas necesarias para resolver aquellas falencias que existen en el diseño de sonido de una pieza, entender como las herramientas condicionan los procesos productivos y proporcionar datos para que en experiencias futuras los resultados obtenidos sean de una calidad aceptable.
¿Qué es el sonido?
El sonido puede entenderse como la vibración mecánica de las partículas del aire, que en contacto con el tímpano, se transmite al oído. A través del oído interno y el nervio auditivo, el cerebro interpreta estas vibraciones. Lo que el cerebro interpreta es lo que oímos.
Podríamos incluso decir que el sonido, la sensación sonora, no existe en absoluto fuera de nosotros; existen solamente fenómenos mecánicos que al transmitirse al nervio auditivo, hacen nacer la sensación, pero que no son la sensación misma. No obstante, por una abusiva extensión de la palabra sonido, la utilizamos para designar el fenómeno objetivo que hace nacer la sensación: así, hablamos de la propagación del sonido, y de su reflexión. En realidad, estas expresiones no tienen ningún sentido, ni el sonido se propaga, ni se refleja, del mismo modo que no pueden hacerlo las demás sensaciones.
De todos modos, estudiaremos en todos los casos estos fenómenos que son los responsables directos de las sensaciones que se producen, en algunos casos subjetivas (posibilidad de interpretación de la carga simbólica de un sonido) y en otros con rasgos generales que hacen que el sonido pueda estudiarse y acotarse para su análisis.
Volviendo al inicio de este apunte, la vibración de una partícula significa que esta se mueve en las proximidades de su posición original y pasada la vibración volverá a su posición original. Una vibración es (por ejemplo) lo que ocurre en la superficie de agua en reposo, si se arroja una piedra: esta crea una vibración que avanza y hace que las partículas de la superficie suban y bajen, pero pasada la onda, las partículas siguen donde estaban.
La diferencia con el ejemplo del agua, es que en el aire los movimientos de las partículas son longitudinales, en la dirección de avance del sonido. Si tenemos una superficie que vibra, como puede ser el cono de un altavoz, la vibración se transmite a las partículas de aire que están en contacto con la superficie, empujándolas hacia adelante y hacia atrás, éstas a su vez empujan a las siguientes y cuando las primeras se retraen (se vuelven hacia atrás) las segundas también y así se va propagando la onda por aire.

Tomando la definición de sonido, como aquello que el oído humano es capaz de percibir, habría que limitarlo a las vibraciones de frecuencias comprendidas entre 20 y 20.000 Hz (Hertzios = ciclos completos en un segundo). De este modo se llamarían infrasonidos a las vibraciones cuya frecuencia fuese menor de 20 Hz y ultrasonidos a las que oscilan por encima de los 20 KHz (kilo hertzios).
Llamaremos de ahora en más espectro audible, todo conjunto de vibraciones comprendidas dentro del rango de 20 Hz a 20 Khz.
Las magnitudes para la medición del sonido:
La acústica aporta dos unidades esenciales para poder medir y comparar entre sí los sonidos. Estas unidades son el Hertzio para la frecuencia y el decibelio para la amplitud. Ambas unidades están siendo utilizadas de un modo muy generalizado en todos los ámbitos en los que se trabaja con sonido. Se han convertido en el punto de partida para cualquier investigación en la que las vibraciones audibles forman parte del objeto de estudio; y son también unidades muy cotidianas en el ámbito de la industria audiovisual.
No obstante, es importante tener muy presente que aunque estas dos magnitudes dan cuenta adecuadamente de las dimensiones estrictamente físicas de los fenómenos vibratorios, están muy lejos de resolver satisfactoriamente la medición de las sensaciones de tono e intensidad.
Técnicamente, la medición física de la frecuencia suele utilizarse en todos los ámbitos como medida de la sensación tonal, a pesar de que ambos son fenómenos perfectamente diferenciados.
La medida de la frecuencia es sumamente simple. Se mide contando el número de oscilaciones por segundo que desarrolla cualquier objeto al sufrir una vibración.
La frecuencia de vibración de un objeto que actúa como fuente sonora se corresponderá con el número de oscilaciones que sufren las moléculas del aire que son estimuladas por él. Y el aire transmite esta frecuencia al oído, que se encargara de traducir la vibración en sensación tonal; o al diafragma del micrófono, que se encargará de traducir la vibración sonora en variaciones de amplitud eléctrica.
La física toma como magnitud de referencia para medir cualquier frecuencia una vibración que tarda un segundo en hacer el recorrido completo desde que parte de su punto de reposo en un sentido y retorna a este punto en el mismo sentido. A esta relación entre la rapidez de la vibración y el tiempo se la denomina: Un ciclo por segundo(1 cps).
Haciendo referencia a esta magnitud es posible comparar con exactitud la rapidez de cualquier vibración con la de cualquier otra. El ciclo por segundo es, pues, la magnitud que se utiliza como unidad para el estudio de grado de rapidez de las vibraciones. A esta unidad se la denomina también Hertz (Hz). Este es el nombre de su creador.
1 Hertz = 1 Ciclo x 1 Segundo

Así, del sonido producido por unas moléculas de aire que oscilan en 150 ocasiones cada segundo se dice que tiene una frecuencia de 150 Hz.
Esta unidad no responde al umbral mínimo de percepción de frecuencia, ya que este es de unos 20 cps.
Una vibración de 1 cps será detectada por un instrumento de medición acústica, pero no por el oído humano. Es una unidad de medida que se ajusta solo parcialmente a la dinámica de la audición en tanto que no contempla la perdida de finura en la sensibilidad que tienen todos los sentidos humanos a medida que va aumentando el estimulo percibido (ley de Weber y Fechner).
Ciertamente existe una relación entre la frecuencia de una vibración medida en Hz, y la sensación tonal que esta produce, ya que cuando aumenta la frecuencia de la vibración sube, también, la sensación tonal. Pero esta relación no es lineal sino geométrica: Cada vez que se dobla la frecuencia solo aumenta en un grado nuestra sensación auditiva de tono.
El sistema musical de occidente ha organizado sus unidades de una forma mucho más ajustada a la sensibilidad del oído humano que la física acústica. La escala tonal estructura su gama de unidades en semitonos, tonos y octavas y de este modo se aproxima bastante más a la estructura de la percepción humana que el estudio en cps o Hz.
Generalmente, existe una clara tendencia a confundir los términos tono y frecuencia; incluso, durante años, fueron sinónimos de una misma propiedad.
Si bien es cierto que el tono percibido guarda una estrecha relación con la frecuencia, el primero siempre es una magnitud subjetiva que depende de la frecuencia fundamental percibida por el oído, condicionado por otras cualidades como son el contenido armónico, la intensidad y la nota. La frecuencia, sin embargo, es una magnitud física, medible y referida a formas de onda periódicas. El tono también aumenta cuando aumenta la frecuencia, pero ambos lo hacen con una variación distinta.
En música, la relación entre el tono y la frecuencia toma especial importancia. Si tocamos la nota más grave de un piano e interpretamos una escala hasta llegar a las notas más agudas del piano, nuestros oídos percibirán que todos los pasos han sido iguales. Sin embargo, la diferencia entre el do y el re más graves es de 4 Hz, mientras que la diferencia entre el do y el re más agudos es de, aproximadamente, 256 Hz.
En música, la relación entre el tono y la frecuencia toma especial importancia. Si tocamos la nota más grave de un piano e interpretamos una escala hasta llegar a las notas más agudas del piano, nuestros oídos percibirán que todos los pasos han sido iguales. Sin embargo, la diferencia entre el do y el re más graves es de 4 Hz, mientras que la diferencia entre el do y el re más agudos es de, aproximadamente, 256 Hz.
Otro ejemplo: si tocamos todas las notas do del piano secuencialmente, en sentido ascendente, musicalmente la distancia entre todas ellas es la misma, una octava; sin embargo, la frecuencia se ha doblado al pasar de un do a otro superior. Este tipo de progresiones recibe el nombre de progresiones exponenciales. Normalmente, en las medidas más cotidianas se emplea una progresión lineal. Por ejemplo, las divisiones de una cinta métrica son idénticas desde el principio al fin. Es evidente que la frecuencia no es adecuada como medida del tono.
Según sea la relación o intervalo entre notas consecutivas, las escalas reciben diferentes nombres: Pentatónicas, Pitagóricas, de Entonación Justa o Igualmente temperada. Esta última es la adoptada de forma universal para los instrumentos de teclado. Sus intervalos de frecuencia son siempre la raíz doceava de dos o 1,059633.
En 1939 se acordó definir la frecuencia del La3 = 440 Hz, a fin de disponer de una referencia internacional ya que, a lo largo de la historia, esta frecuencia ha variado desde los 373 hasta 472 Hz.
Es evidente que multiplicando o dividiendo la frecuencia de este La central por 1,059633, se obtendrá la frecuencia de todas las notas de la escala musical temperada. Como se verá, cada 12 intervalos, la frecuencia de la nota dada, sufre un salto al doble o la mitad de ésta. Dicho salto se denomina Octava.
La magnitud acústica para medir frecuencia, por si sola, tampoco da cuenta de un modo satisfactorio de los sonidos compuestos. De hecho, el concepto de frecuencia en su sentido más estricto solo es satisfactorio para los sonidos simples. En el momento en que nos enfrentamos a un sonido compuesto, es necesario diferenciar entre frecuencia fundamental, armónicos y parciales. Cuando se habla de frecuencia de un sonido compuesto, normalmente se esta haciendo referencia a su frecuencia fundamental, al ser esta la que tiene una influencia perceptiva mas clara en la sensación tonal. No obstante, el resto de las frecuencias que componen los sonidos complejos influyen también de una forma determinante en la sensación auditiva (timbre) que estos producen. Así, el concepto de frecuencia por sí solo resulta demasiado simple para cuantificar adecuadamente este fenómeno perceptivo.
La medición de la Intensidad :
Mientras que la frecuencia hacia referencia exclusivamente al fenómeno vibratorio, y por tanto físico, el concepto de intensidad hace referencia ya de forma directa a la sensación psicológica de energía del sonido. Veremos que la acústica ha resuelto bastante mejor la medida de la amplitud de las vibraciones sonoras que la medida de su frecuencia, al introducir en la medición de la energía sonora la perdida progresiva de finura del sistema sensorial humano con el aumento de la energía de los estímulos. No obstante, encontraremos también algunos problemas más en la cuantificación de la intensidad.
La definición de la unidad de medida de la intensidad es bastante más compleja que la de la frecuencia y hemos de partir de algunas consideraciones previas sobre la percepción antes de llegar a ella.
Como hemos dicho ya, el ser humano pierde finura en la sensibilidad de todos los sentidos a medida que aumenta físicamente la intensidad del estímulo percibido. Si comparamos por ejemplo el peso de dos paquetes pequeños de 100 g y 150 g respectivamente, poniendo uno en cada mano somos perfectamente capaces de percibir la diferencia y decir cual de los dos es el más pesado. Es decir, afinamos a distinguir 50 g de diferencia. Pero si esta comparación la hacemos con paquetes de 10050 g y 10000 g utilizando la misma técnica seremos incapaces de notar diferencia alguna. Para percibir la misma sensación diferenciadora que tuvimos entre 100 y 150 gramos deberíamos tener en una mano 10 kg . Y en la otra 15 kg .
Es decir, para sentir lo mismo que antes podíamos percibir con 50 gramos , al aumentar la intensidad del estímulo necesitamos una diferencia de peso 100 veces mayor. Exactamente la misma proporción con la que ha aumentado globalmente el estímulo a comparar.
Este fenómeno fue sistematizado por la ley de Weber y Fechner, que se formula de la forma siguiente: “La percepción es proporcional al logaritmo de la excitación”. O lo que es lo mismo: “La sensación crece sólo en progresión aritmética mientras que la excitación que la provoca crece proporcionalmente en progresión geométrica”.
Volviendo al ejemplo de la comparación de 100 gramos y 150 gramos de peso entre las dos manos, si la percepción es proporcional al logaritmo de la excitación, calculando el logaritmo de los pesos tendremos una idea de la sensación que estos transmiten. Veámoslo:
Log 100 = 2 y Log 150 = 2,17
Así la sensación percibida es de:
2,17 – 2 = 0,17
Si lo que comparamos son 10 Kg . Con 10 Kg . más 50 g
Log 10000 = 4 y Log 10050 = 4,002
La diferencia percibida es de:
4,002 – 4 = 0,002
Para conseguir la misma diferencia de sensación (0,17), el peso en la mano que aguanta una carga mayor debería ser igual a la inversa del logaritmo de (4 + 0,17). O sea, el peso debería ser de 104,17 . Haciendo el cálculo:
104,17 = 14,791 g (unos 15 Kg .)
Estudiaremos ahora la unidad clásica de intensidad sonora que es el decibel (Db). Esta magnitud intenta relacionar la percepción humana con la cuantificación física de la presión que producen las vibraciones sonoras del aire al incidir sobre el oído. Es una medida relativa que toma como referencia a la mínima presión sonora que es capaz de percibir el oído humano. Y compara la presión ejercida por cualquier sonido con esa magnitud.
A partir de aquí desarrollaremos paso a paso todo el proceso de construcción conceptual y matemática del decibel o decibelio.
Esta unidad trabaja desde el sistema cegesimal (centímetros, gramos, segundos) y toma como referencia una frecuencia pura de 1000 Hz. La razón por la que se toma una referencia de 1000 Hz es que la percepción de la intensidad no solamente varia con la amplitud de la vibración, sino que varia, también, en función de la frecuencia. Escuchando una frecuencia de 1000 Hz estamos en la zona frecuencial para la que el oído humano tiene una respuesta sensible más regular a la amplitud de las vibraciones sonoras.
El punto de partida es el fenómeno físico: Concretamente, la presión que ejercen las moléculas de aire, que han sido estimuladas por una fuente sonora, al vibrar sobre el tímpano humano. Aproximadamente, la presión mínima que puede percibir el oído es de 0,0002 dinas/cm2
Esta cantidad se tomó como magnitud de referencia (P0) con la que se compararía cualquier otra presión acústica (P1) sobre el oído. Es decir, como unidad. Así se podría conocer el grado de presión auditiva de cualquier sonido calculando el número P0 que contuviera. La presión auditiva seria pues:
Presión Auditiva = P1 / P0
A partir de aquí era necesario encontrar el otro extremo: La máxima presión sonora perceptible, y construir una escala entre estos dos límites de la sensibilidad humana a la intensidad.
La máxima presión humana que el oído podía aguantar antes de llegar al umbral del dolor era de 1 billón de veces la presión mínima. Es decir 1012 x 0,0002 dinas/cm2. Con lo que desde el umbral mínimo hasta el umbral máximo aparecía una escala de un billón de grados, que resultaba absolutamente inmanejable. No obstante, trabajando matemáticamente con potencias de 10 se podía diseñar una escala solo de 12 grados desde la sensibilidad mínima hasta la máxima. O sea:
Si 1000000000000 = 1012
Los grados podían ser:
101, 102, 103, 104, 105,..., 1012
Además, se había observado ya que la sensación que percibe el ser humano es siempre proporcional al logaritmo de la cantidad de excitación: por lo tanto el cálculo de la sensación de sonoridad de potencia sonora, debería ajustarse también a esta ley. Así en realidad, la sensación de intensidad se ajusta al logaritmo del cociente entre la presión sonora que incide sobre el tímpano (P1), dividida por la presión sonora mínima que puede percibir el oído (P0). Es decir:
Intensidad = Log (P1 / P0)
Dando al umbral mínimo de presión auditiva (P0) el valor de unidad: 1, y hacer este calculo tomando como P1 la máxima de presión audible, se obtuvo la cifra: 12, como valor que expresaba la máxima intensidad audible. Veámoslo:
Intensidad = Log (1012 / 1) = 12
Quedaba, pues, definido así el máximo de una escala relativa de 12 grados que se aproximaba a la sensación de intensidad. A la unidad de esta escala se la denominó Bel. La máxima intensidad que soporta el oído es, pues de 12 bels. No obstante, el Bel no era adecuado como unidad para medir las pequeñas variaciones de intensidad. En realidad el Bel resultaba una unidad demasiado grande, demasiado gruesa para la sensibilidad auditiva humana. Se decidió entonces dividir el Bel en 10 unidades más pequeñas, con lo que se obtenía definitivamente el decibel. Tenemos pues que:
1 bel = 10 decibeles
Lógicamente, para calcular la sensación de intensidad en decibeles (dB), será necesario multiplicar por 10 el número en bels. El umbral del dolor, por ejemplo, es de 12 bels x 10 = 120 decibeles o decibelios. Ahora, la sensación de intensidad que produce un sonido se podía predecir de forma bastante aproximada calculando el número de decibelios que tiene el sonido en cuestión mediante la siguiente formula:
Intensidad (en dB) = 10 Log (P1 / P0)
Siendo P0 la magnitud o unidad de referencia (en este caso 0,0002 dinas/cm2) y P1 la presión que ejerce el sonido en cuestión expresada en las mismas unidades de referencia.
Finalmente, cuando la impedancia acústica es constante, o dicho de otro modo, cuando la capacidad de penetración del sonido en el aire es constante, tal como ocurre en las investigaciones acústicas, las potencias acústicas resultan proporcionales al cuadrado de las presiones acústicas. Aplicando esto, el calculo de la intensidad en dB queda del siguiente modo:
Intensidad (en dB) = 10 Log P12 / P02
O lo que es lo mismo:
Intensidad (en dB) = 20 Log P1 / P0
El decibelio ha sido homologado internacionalmente como unidad de medida, dándole un valor concreto de presión, exactamente el de 0,000204 dinas/cm2. Este es el valor medio de la mínima presión audible, determinado a 1000 cps.
Al estudiar el dB, hemos visto que todo el desarrollo de esta unidad está hecho tomando como referencia una vibración simple de 1000 cps. Lógicamente, eso supone, también, que aunque obtengamos, por ejemplo, dos medidas idénticas de 50 dB de presión sonora en sendos sonidos de 100 Hz y de 1000 Hz, no tenemos ninguna garantía de que estos sonidos vayan a transmitir la misma sensación psicológica de intensidad. De hecho esto es justamente lo que ocurre. La sensibilidad humana a la presión auditiva es menor cuando el sonido que escuchamos es de frecuencia más baja y va aumentando a medida que aumenta la frecuencia del sonido.
Esto ocurre hasta aproximadamente los 3000 Hz. A partir de esa frecuencia, la sensibilidad del oído a la presión sonora vuelve a disminuir progresivamente, hasta que desaparece en torno a los 15000 a 20000 Hz.
Sucede entonces que un sonido que tenga una frecuencia de 100 Hz y una presión sonora de 20 dB, no puede ser percibido por el oído humano, mientras que si esta misma presión sonora de 20 dB llega a nuestro oído asociada a una frecuencia de 1000 Hz, si que será perfectamente audible.
Esto puede explicarse de la siguiente manera por las curvas de igual sonoridad propuestas por Fletcher-Munson

Las líneas discontinuas marcan los niveles de presión necesarios a cada frecuencia, para que el oído detecte (subjetivamente) la misma sonoridad en todas. Esto quiere decir que si reproducimos un tono de 31.5 Hz a 100 dB (NPS), luego otro de 63 Hz a 90 dB y otro de 125 Hz a 80 dB, el oyente dirá que todos sonaban al mismo volumen.
En 2 KHz el umbral de audición se fija en 0 dB y a 4 KHz es incluso menor de 0 dB, ya que a 3600 Hz se encuentra la frecuencia de resonancia del oído humano.
Por debajo de 2000 Hz y según se va bajando en frecuencia, el oído se vuelve menos sensible. Los umbrales de audición para frecuencias menores de 2 KHz son: 5 dB a 1 KHz, 7 dB a 500 Hz, 11 dB a 250 Hz, 21 dB a 125 Hz, 35 dB a 63 Hz, 55 dB a 31 Hz. Recuerde que estos dB's son de nivel de presión sonora (NPS o SPL).
Por encima de los 4 KHz, el oído es menos sensible, pero no tanto como en bajas frecuencias. Sin embargo, se producen fluctuaciones a frecuencias cercanas, debido a las perturbaciones que produce la cabeza del oyente en el campo sonoro. Los umbrales de audición son: 15 dB a 8 KHz y 20 dB a 16 KHz
Todos los receptores de sonido, tienen un comportamiento que varía con la frecuencia. En el caso del oído humano, sucede lo mismo, ya que se trata el receptor más complicado y (aunque parezca extraño) más eficiente que existe.
El umbral de audición define la mínima presión requerida para excitar el oído. El límite del nivel de presión sonora se sitúa generalmente alrededor de 130 dB, coincidiendo con el umbral del dolor (molestias en el oído). La pérdida de audición de manera súbita, por daños mecánicos (en el oído medio) se produce a niveles mucho mayores. La exposición suficientemente prolongada a niveles superiores a 130 dB produce pérdida de audición permanente y otros daños graves.
En acústica, las frecuencias siempre se tratan de manera logarítmica: representaciones, gráficas y demás. El motivo principal es que el oído humano interpreta las frecuencias de manera casi logarítmica. En el eje de frecuencias de cualquier gráfica de las vistas hasta ahora, las marcas pasan de una frecuencia (p. ej. 1000 Hz) al doble (2000 Hz). La apreciación subjetiva de un oyente será que hay la misma distancia entre un tono de 200 Hz y otro de 400, que entre uno de 1000 Hz y otro de 2000 Hz. Sin embargo la "distancia" en frecuencia en el primer caso es de 200 Hz y en el segundo de 1000 Hz.
Lo simple y lo complejo – Estructura de un sonido:
Los sonidos nos llegan como un todo, en donde su aparente simpleza oculta un carácter más complejo que en este apartado definiremos. Si bien aun no hemos definido a la frecuencia como concepto diremos que los sonidos están compuestos por un conjunto de frecuencias organizadas que varían sus características de acuerdo a como se define esta organización.
El patrón organizativo de este entorno de frecuencias, entendiendo al entorno como un conjunto de frecuencias con dos limites precisos que caen dentro del espectro audible, se verá modificado o alterado de acuerdo a que o a quién se constituya como objeto sonoro, en dónde se reproduzca el evento sonoro, que elementos formen parte de la cadena de audio que puedan alterar este patrón de frecuencias, y por último quién percibe el sonido como tal.
Ahora bien, llamaremos sonidos compuestos a aquellos que, valga la redundancia, están compuestos por un número mayor a dos frecuencias, mientras que serán simples todos aquellos sonidos que están conformados por una única frecuencia.
Los sonidos de una única frecuencia, se llaman tonos puros. Un tono puro se escucha como un "pitido”. El sonido que se escucha en el teléfono antes de marcar, por ejemplo, corresponde a un tono puro de frecuencia cercana a 400 Hz. El tono de la "carta de ajuste" de la televisión, corresponde a una frecuencia de 1000 Hz.
Es muy sencillo establecer ejemplos de a que llamamos sonidos compuestos ya que la totalidad de lo que escuchamos (exceptuando los sonidos simples) como las voces, los sonidos de los instrumentos musicales, el fondo de una ciudad, el sondo del canto de un pájaro, etc. caen dentro de esta categoría.
Esta organización compuesta de ninguna manera es caótica, podemos asignarle un “valor” a cada una de las frecuencias de un sonido compuesto que como veremos más adelante esta estructuración tendrá un rol primordial a la hora de poder desde comprender o analizar un sonido hasta pensar en su post-tratamiento.
Para comprender esto, pensaremos en un sonido compuesto que, casi en el borde de la simpleza, está integrado por tres frecuencias, a ser: 120 Hz, 240 Hz y 241 Hz.
Llamaremos Frecuencia Fundamental, a la menor de las frecuencias que integran el sonido compuesto y que servirá de patrón organizativo del resto del conjunto (entorno) de frecuencias. En nuestro ejemplo, la fundamental es la frecuencia de 120 Hz.
Observemos ahora que nos quedan por analizar otros dos elementos, la frecuencia de 240 Hz y otra de 241 Hz. A simple vista podemos ver que entre la frecuencia fundamental y la frecuencia de 240 Hz hay una evidente relación: 240 es múltiplo de 120. Por ende, llamaremos armónicos o frecuencias armónicas a todas aquellas que sean múltiplos de la fundamental.
Para finalizar toda aquella frecuencia que no sea múltiplo de la fundamental y por ende de sus respectivos armónicos, la denominaremos parcial.

Esta estructuración tiene como correlato un mejor entendimiento de un concepto que es sumamente complejo y discutido, el de timbre, para lo cual propondremos una serie de definiciones que darán luz sobre el tema.
El concepto de timbre no es acústico sino psicológico. El timbre es una sensación auditiva compleja (independiente de las de duración, tono e intensidad y simultánea a ellas) que nos permite percibir la estructura acústica interna de los sonidos compuestos.
En una primera aproximación, podemos encontrar en la sensación tímbrica tres dimensiones bien diferenciadas: Armonicidad, Impresión Espectral y Definición Auditiva. Veamos con detalle cada uno de estos tres conceptos.
Armonicidad: Distinto grado de limpieza y agradabilidad que percibimos al escuchar un sonido compuesto, dependiendo de la relación que existe en su espectro entre armónicos y parciales. Cuanto mayor sea la gama de frecuencias organizadas armónicamente, mayor será la sensación de limpieza y agradabilidad, es decir mayor será la armonicidad. Cuanto mayor sea la superficie espectral ocupada por armónicos, mayor será la sensación de armonicidad.
Impresión Espectral: La organización de las resonancias o formantes a lo largo del espectro configuran una sensación tímbrica que podríamos denominar genéricamente como impresión espectral. Definiremos el concepto del siguiente modo:
Llamaremos impresión espectral a la sensación de diferente matiz auditivo que percibe un receptor, cada vez que escucha un sonido de idéntica composición de frecuencias, pero con distinta envolvente espectral. Entendiendo como envolvente espectral la forma obtenida al trazar una línea que une todas las puntas de la cresta de cualquiera de sus espectrogramas posibles. Se denomina formante a la gama de frecuencias de un sonido compuesto que han quedado reforzadas en amplitud por la forma y el volumen del espacio en el que se está propagando el sonido en cuestión.
Definición Auditiva: Para desarrollar y explicar este concepto perceptivo estableceremos un símil con la terminología utilizada para hablar de la sensación de detalle visual en la reproducción de imágenes.
Denominaremos definición auditiva a la sensación de máximo grado de precisión exactitud o detalle sonoro que percibe el oyente al escuchar atentamente un sonido.
Propagación del Sonido:
Reflexión y Transmisión:
Cuando una onda acústica incide sobre una superficie plana que separa dos medios, se producen dos ondas: una de reflexión y otra de transmisión. Cuando la inclinación de la onda incidente es superior a una ángulo dado (ángulo crítico), sólo se produce onda reflejada. Cuanta energía pasa a formar parte de la onda reflejada y cuanta pasa ser parte de la onda transmitida, es función de la relación de impedancias acústicas entre el primer y el segundo medio. La impedancia es la oposición que hace el medio al avance de la onda, algo así como la "dureza" del medio. Cuando se pasa del medio aéreo al acuático, casi toda la energía se refleja, debido a que las impedancias son muy dispares. En cambio, entre una capa de aire frío y otra de aire caliente, casi toda la energía de la onda acústica pasa a formar la onda transmitida, ya que la impedancia acústica es parecida.

Ondas que se generan al pasar de un medio a otro.
Absorción:
Una onda acústica implica el movimiento de partículas, las cuales rozan entre sí. Este roce consume parte de la energía, que se convierte en calor, disminuyendo la energía acústica total. La pérdida de energía, o absorción, depende de cada frecuencia, siendo generalmente mayor a altas frecuencias que a bajas frecuencias.
En medios fluidos como el aire o el agua se pueden dar los datos de absorción en función del camino recorrido por la onda acústica. La siguiente tabla muestra la absorción del aire a 20º centígrados y humedad del 70% para distintas frecuencias, en dB por kilómetro.
Frecuencia (Hz) | 31 | 63 | 125 | 259 | 500 | 1K | 2K | 4K | 8K | 16K |
Absorción (dB/Km.) | 0.2 | 0.3 | 0.7 | 1.3 | 2.6 | 5.3 | 11.0 | 22.0 | 53.0 | 160 |
Como se puede observar, la absorción es mucho mayor en las altas frecuencias que en las bajas. Por ejemplo, una onda acústica de frecuencia 500 Hz que recorre dos kilómetros sufre unas pérdidas por absorción del aire de 5.2 dB. Para calcular el nivel real, habría que tener en cuenta las pérdidas por divergencia esférica.
También existe otro parámetro de la absorción, y es el que se usa en las especificaciones de materiales acústicos. Se suele llamar "coeficiente de absorción a:", es adimensional y sus valores van de 0 a 1, siendo cero equivalente a mínima absorción y uno máxima absorción. Este valor se usa principalmente para calcular los tiempos de reverberación de salas. El coeficiente "a:" de un panel acústico depende principalmente del espesor, porosidad y de la forma que tenga.
Difracción:
Se entiende por difracción cualquier desviación de la propagación en línea recta debida a la presencia de algún obstáculo en el medio homogéneo. Por ejemplo, un muro que separa una zona residencial y una carretera, ya que no se interrumpe el medio de propagación: el aire. De forma parecida a como actúa la luz cuando se encuentra con un obstáculo, actúan las ondas acústicas. También se puede hablar de sombra acústica creada por un obstáculo. La sombra creada es distinta según la frecuencia de la que se trate.
Así las altas frecuencias "proyectan" una sombra más definida que las bajas frecuencias. Es decir, si entre el oyente y una fuente sonora que están en campo abierto, se sitúa un obstáculo (por ejemplo se levanta una pared de dos metros), el oyente percibirá una reducción de la intensidad del sonido total. Sin embargo, esta reducción será poca a las frecuencias próximas a 20 Hz (bajas frecuencias) y mucha a las frecuencias próximas a los 20 KHz (altas frecuencias), alrededor de 10 dB. En este caso se podrá decir que las bajas frecuencias sufren más difracción que las altas, en otras palabras: su trayectoria se ha curvado más, rodeando el obstáculo.
Frecuencia Atenuación del NPS
250 Hz 14 dB
500 Hz 17 dB
1000 Hz 20 dB
2000 Hz 23 dB

Datos de un ejemplo real. A la izquierda la fuente de ruido, a la derecha el oyente.
Los efectos de difracción pueden tener importancia para micrófonos, altavoces, para la audición humana (difracción sobre la cabeza, que hace de obstáculo), para el diseño acústico de recintos... Las sombras acústicas creadas por obstáculos son muy usadas en la lucha contra el ruido, como por ejemplo, los paneles usados en autopistas o autovías (en algunos lugares) para evitar que el sonido de los vehículos que circulan por ellas alcancen a las casas colindantes.
Enmascaramiento:
El enmascaramiento de un tono o de un ruido de banda estrecha sobre otro, es una experiencia diaria. Cuando se encuentra dificultad o imposibilidad para escuchar algún sonido (música, habla...) porque otro sonido (considerado ruido) está presente en el mismo momento, estamos sufriendo enmascaramiento.
Los procesos de enmascaramiento cumplen siempre:
a) Una banda estrecha de ruido, produce más enmascaramiento que un tono puro de igual frecuencia central y misma intensidad.
b) Cuando el ruido es de bajo nivel, el enmascaramiento se produce en una banda de frecuencia estrecha alrededor de la frecuencia central del ruido.
c) El efecto de enmascaramiento no es simétrico en torno a la frecuencia central del ruido enmascarante. Las frecuencias superiores sufren más los efectos de enmascaramiento.

La gráfica muestra las zonas que estarían bajo los efectos del enmascaramiento, con un ruido de banda estrecha centrado en 1200 Hz, y para distintos niveles de presión sonora del ruido. Para el caso más extremo, el ruido de 110 dB (la curva más alta), obtenemos la mayor zona enmascarada. Por ejemplo, en este caso, el oyente no detectaría un tono de 8 Khz. y 50 dB de nivel de presión; tampoco detectaría un sonido de 4 Khz. y 70 dB de nivel de presión...
Localización Espacial de Fuentes:
En el caso más general, en campo abierto, el cerebro localiza la fuente de sonido, basándose en la diferencia de nivel entre un oído y otro, y en la diferencia de tiempo (retardo) entre un oído y otro. Como se había dicho, el sonido viaja a una velocidad de 343 m/s y la separación entre oídos es de unos 20 cm , los posibles retardos llegan hasta 600 µs (1 microsegundo = 0.000001 segundo). La diferencia de nivel entre los oídos, es debido principalmente a la "sombra" de la cabeza, este efecto se acusa más en altas frecuencias. Las altas frecuencias se localizan principalmente por diferencia de nivel, y las bajas por diferencia de fase (retardo). Para acabar de localizar la fuente del sonido, está el movimiento de la cabeza, que es algo instintivo y colabora de forma determinante a la ubicación de la fuente.
En este apartado, nos centraremos en un caso concreto de los posibles: dos fuentes sonoras emitiendo señales coherentes. Se elige este caso porque es el más general. Los dos altavoces de un sistema estéreo emiten, en su mayor parte señal coherente, es decir, la misma señal.
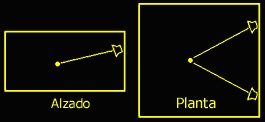
La posición estéreo por definición, es cuando los altavoces y el oyente forman un triángulo equilátero de tres metros de lado. Además se suelen elevar los altavoces unos pocos grados sobre el plano de audición.
Para simular los distintos efectos se suelen añadir retardos entre los dos altavoces, mediante la electrónica. Se puede añadir retardo a toda la señal, o sólo a unas frecuencias para crear distintos ambientes. Si el oyente se sitúa a la misma distancia de los dos altavoces, los escucharía al mismo nivel, suponiendo que la señal que entra ambos altavoces es la misma, sólo con posibles retardos. Variando solamente el retardo entre altavoces, tendríamos los siguientes casos:
a) Retardos entre 0 y 630 µs: el oyente identifica que hay una única fuente de sonido cuya posición depende del retardo entre las dos señales. El cerebro "suma" las señales de los dos oídos para determinar la posición de la fuente. Este efecto se denomina "Localización Suma" y es la base de los efectos estereofónicos con dos altavoces.
b) Retardos entre 1 ms y 40-50 ms (1 milisegundo = 0.001 segundos): el oyente identifica una única fuente sonora que sitúa en la posición del altavoz cuya señal está llegando primero a sus oídos (el que no está retardado). Las componentes de señal que llegan a los oídos en primer lugar son tomadas en consideración y las últimas son suprimidas en el proceso de cálculo. Este es el llamado efecto del "Primer Frente de Onda", muy importante a la hora de diseñar sistemas de refuerzo sonoro mediante varios altavoces, por ejemplo en salas de cine.
c) Retardos superiores a 50 ms: el oyente identifica dos fuentes de sonido, cada una en la posición de un altavoz. La segunda fuente de sonido será denominada eco de la primera.
Los límites de los márgenes de los retardos no son invariables, ya que dependen también de las condiciones ambientales del experimento y también de la percepción subjetiva de cada individuo. Por ejemplo, para retardos entre 630 µs y 1 ms, se tendrá "Localización Suma" o "Ley del Primer Frente de Onda" en función del sujeto y de las condiciones del experimento.
Cadena de Audio – La Cadena Electroacústica
Para poder registrar un sonido o tan solo escucharlo a través del recorrido de una cadena de audio, necesitamos comprender cada uno de los eslabones que representan esta cadena. Como veremos más adelante, la construcción de esta cadena surge de la analogía de lo que sucede en la naturaleza con el sonido: Necesitamos en primera instancia un cuerpo vibratorio que produzca estas vibraciones dentro del rango representado por el espectro audible, un medio por donde el sonido pueda transitar y otro cuerpo que interpretara estas vibraciones (con lo complejo que esto puede llegar a ser si pensamos en la díada percepción-interpretación).
Para lograr esta necesidad de reproducir un sonido la técnica ha aportado la siguiente solución:
En el punto inicial de la cadena como siempre conservamos al cuerpo vibratorio, sin el cuál obviamente no se podría generar sonido. Para poder captar estas vibraciones y encaminarlas dentro de la cadena de dispositivos necesitaremos un “algo” que pueda transformar estas variaciones de presión en variaciones de tensión. Este “algo” es lo que conocemos como micrófono. Sin embargo, esta transformación es insuficiente para que nuestro oído pueda interpretar esta información por dos razones. Por una parte nuestro oído solo es capaz de reconocer vibraciones que se representen dentro del marco que propone el espectro audible, no así corriente eléctrica. Y por otra parte esta tensión generada por el micrófono es aún muy débil como para poder estimular a otro cuerpo para poder producir vibraciones.
Esta es la razón de la existencia de otro de los componentes fundamentales de la cadena, el amplificador, que se encarga de aumentar esta tensión a un nivel necesario para poder movilizar la bobina de un parlante (otro de los elementos de la cadena) para que este vibre y mueva al aire (el medio) para poder producir nuevamente vibraciones que lleguen al oído.
En una cadena de audio ideal, estas vibraciones iniciales serían proporcionales a las vibraciones finales, donde ningún elemento que forma parte de la cadena de audio distorsiona la información inicial. Sabemos que esto no es así ya que se verifica que la relación inicial donde las variaciones de voltaje (que salen del micrófono) son proporcionales a las variaciones de presión del aire, se ven influenciadas por un índice de distorsión que surge de distintos factores.
Como ya imaginamos, este índice de distorsión se va acrecentando a medida que interconectamos dispositivos, y estas distorsiones o modificaciones en la señal son producto de un conjunto de fenómenos que estudiaremos a continuación
Respuesta en frecuencia:
Se llama respuesta en frecuencia al comportamiento de un dispositivo de audio frente a las distintas frecuencias que componen el espectro de audio (20 a 20.000 Hz).
Todos los dispositivos de audio cumplen una función determinada, los micrófonos recogen vibraciones acústicas y las convierten en señales eléctricas (que igualmente tendrán módulo, fase y frecuencia). Los altavoces convierten señales eléctricas en vibraciones acústicas. Todos los dispositivos manejan frecuencias de audio, pero no reaccionan igual ante todas las frecuencias.
De igual forma que el oído humano no escucha igual todas las frecuencias, los micrófonos tampoco, ni los amplificadores trabajan igual con todas igual, ni los altavoces son capaces de reproducir todas las frecuencias por igual. Esta última es la razón por la que en la mayoría de los equipos domésticos, hay por lo menos dos altavoces distintos por caja. Uno para reproducir las frecuencias graves y otro para reproducir las frecuencias altas.
Estas variaciones de respuesta conforme varía la frecuencia se miden en dB (decibelios) y se pueden representar gráficamente. La retícula sobre la que se suelen representar es la siguiente:

Escala logarítmica en el eje horizontal (frecuencia) y lineal en el vertical (dB).
En el eje horizontal se representan las frecuencias de forma logarítmica (similar a como el oído escucha). La primera frecuencia marcada es la de 100 Hz, la marca anterior será la de 90 y la siguiente la de 200 Hz, la siguiente de 300 Hz... y así hasta llegar a 1.0 K que son 1000 Hz. La siguiente marca será de 2000 Hz. y así hasta 20.000 Hz. En este caso se representa el espectro desde 90 Hz. a más 20.000 Hz, pero el rango de frecuencias que se tome variará según las necesidades. Si por ejemplo se representa la respuesta en frecuencia de un altavoz de graves, la gráfica deberá empezar en 20 Hz. y no será necesario que se extienda a más 1.000 o 2.000 Hz.
En el eje vertical se encuentran las variaciones de nivel expresadas en dB (10 Log (medida de referencia) ). En esta representación cada salto es de 6 dB, pero las representaciones pueden variar según el grado de definición.
Veamos un ejemplo práctico: respuesta en frecuencia de un altavoz genérico de frecuencias medias.

Gráfica de respuesta en frecuencia.
A la vista de la gráfica se diría que este altavoz tiene una respuesta en frecuencia de 450 Hz. a 4 KHz. con una variación de +/- 3dB. Caídas de más de10 dB en la respuesta en frecuencia equivale a decir que el aparato no trabaja en esa frecuencia. De este altavoz conocemos a través de la gráfica de respuesta en frecuencia que si se le alimenta con dos señales de igual nivel, una por ejemplo de 800 Hz. y otra de 4000 Hz, la segunda tendrá un nivel de presión sonora (NPS) 6 dB menor que la señal de 800 Hz. Esto significa que reproduciendo música o cualquier otra señal, las frecuencias cercanas a 800 Hz. se escucharán más que las cercanas a 3 KHz.
El caso más favorable (e imposible) de respuesta en frecuencia sería una línea recta que cubra todo el espectro. En este caso hablaríamos de respuesta en frecuencia plana. Como esto es imposible, se suele hablar de la "zona de respuesta plana", aunque realmente se trata de una aproximación. En el caso anterior diríamos que la zona de respuesta plana es la definida entre 800 y 3000 Hz, ya que en esta zona es donde es útil el altavoz.

Zona de respuesta idealmente plana entre 200 Hz y 10 KHz
El oído humano tiene dificultad para detectar variaciones de nivel de presión de menos de 0.3 dB. Esto significa que si exponemos a una persona a un ruido (sonido continuo) y vamos variando el nivel de presión sonora (dando más volumen o menos al ruido), el sujeto notará variación cuando la diferencia de NPS (nivel de presión sonora) antes y después se aproxime a los 0.3 dB. Esto da una idea, de cuanta variación de respuesta en frecuencia es aceptable, por ejemplo en unos altavoces.
Este apartado ha tenido como ejemplo un altavoz; sin embargo todos los aparatos de audio tienen su respuesta en frecuencia característica. En una cadena se sonido, donde la señal pasa por varios equipos uno tras de otro, las respuestas en frecuencia de cada aparato se van sumando para conformar la respuesta en frecuencia total del equipo completo.
Supongamos que tenemos un reproductor de CD cuya señal cubre casi todo el espectro de audio (rojo). La señal de este entra en un amplificador con una respuesta en frecuencia definida (verde). La señal que sale del amplificador ataca a un sistema de altavoces con otra respuesta definida (morado).

Respuesta en frecuencia de tres sistemas. Representación superpuesta.
La respuesta en frecuencia del conjunto de aparatos será la suma en dB de todas (azul). El amplificador del ejemplo provoca una caída en la respuesta de 6 dB a 6600 Hz y el sistema de altavoces provoca 6 dB de caída a esa misma frecuencia, la respuesta total tendrá una caída de 12 dB en esa frecuencia.

Respuesta en frecuencia total de los tres sistemas en cadena
Como se ha dicho, todos los elementos por los que pasa la señal de sonido en una cadena de audio (o una cadena de música) van dejando su huella en el espectro de la señal, recortándola y limitándola. Es por esto que es importante que todos los equipos por los que atraviesa la señal de audio tengan la máxima calidad posible. En cualquier caso todos han de ser de calidad similar, ya que el elemento de peor calidad será el que pondrá el límite a la calidad del conjunto.
Actualmente, gracias al desarrollo de la electrónica, los equipos electrónicos suelen tener una respuesta en frecuencia bastante buena. El punto crítico suele estar en los altavoces, que son elementos mecánicos que no han evolucionado tanto como la electrónica por lo que sigue siendo muy costoso fabricar buenos altavoces. Suelen ser los altavoces los que más limitan la respuesta en frecuencia del conjunto y por lo tanto la calidad del conjunto. Por este motivo en las cadenas domésticas, un parámetro de calidad a tener en cuenta son los altavoces, ya que la electrónica es muy similar en todos los casos.
Distorsión:
En el sentido más general existe distorsión cuando la señal que sale de un equipo no es la misma que entró. La distorsión es otra medida de calidad de uso generalizado y suele ser dada por el fabricante.
Hay diferentes tipos de distorsión: distorsión lineal (de amplitud y de fase) y distorsión no lineal (THD y IMD).
- Distorsión Lineal de Amplitud o Distorsión de Amplitud:
Se da cuando la señal a la salida del equipo no guarda la misma relación de amplitud entre las distintas frecuencias que la señal de entrada. Por ejemplo, a la entrada la señal tiene 10 dB de diferencia entre la banda de octava de 1000 Hz. y la de 2000 Hz, pero a la salida la diferencia es de 20 dB. Se ha producido distorsión de amplitud. La respuesta en frecuencia es una representación de la distorsión de amplitud. Un amplificador, por el hecho de elevar el nivel de la señal, no produce distorsión de amplitud, ya que eleva el nivel de todas las bandas de frecuencia en un número de decibelios para todas igual.
Existe un tipo concreto de distorsión, relacionada con la amplitud, que se llama distorsión por recorte. Se da en los equipos que amplifican la señal cuando trabajan por encima de sus posibilidades y consiste en un "recorte" de la forma de onda. Se produce porque al amplificador se le exige que amplifique la señal tanto, que los valores de tensión de pico de la señal, son superiores a los valores de tensión que da la fuente de alimentación. Por un principio básico, la máxima tensión posible que puede dar a la salida un equipo, es la que entrega la fuente de alimentación. Para seguir cumpliendo este principio la señal a la salida se recorta para valores superiores a los de la tensión de alimentación. Antes de que la distorsión por recorte sea audible, los valores de otras distorsiones se han disparado, ya que se está trabajando muy por encima de las capacidades del aparato.

Amplificador trabajando en saturación, entrega señal recortada a la salida.
- Distorsión Lineal de fase o distorsión de Fase:
Se da cuando a la salida no se conserva la relación de fase entre las diferentes frecuencias de entrada. Este tipo de distorsión se da en todos los aparatos electrónicos y es muy difícil eliminarla. Los aparatos HI-FI de alta gama tratan de minimizar al máximo esta distorsión o compensarla, esto explica (en parte) su alto coste y la ausencia de funciones optativas que añaden electrónica y distorsión de fase. Por suerte, el oído tiene dificultad para detectar la fase y por eso (y por la dificultad de su tratamiento) la mayoría de equipos no abordan el problema.
Los dos tipos de distorsión anteriores no se suelen ser facilitados por el fabricante. El primero porque se supone que no existe o porque ya se da la "respuesta en frecuencia". El segundo porque no se suele tratar este problema y el usuario común no lo va detectar.
- Distorsión no lineal THD o Total Harmonic Distorsion:
Esta distorsión se produce por la aparición de armónicos de la señal original. Un armónico es una señal de frecuencia múltiplo de otra original. Si a la entrada tenemos un tono puro de frecuencia 1 KHz, sus armónicos aparecerán como tonos puros de frecuencia 2 KHz, 3 KHz, 4 KHz... Cuando hay distorsión armónica, los armónicos simplemente aparecen pese a no ser deseados.
A continuación se muestra una representación del espectro de salida de un aparato con distorsión armónica. A la entrada del aparato sólo se le conecta un tono puro de f = 1 KHz. Así es como se suele medir la THD.

Espectro de un tono puro (1kHz) con sus armónicos producidos por la THD.
La figura muestra algo parecido a lo que se vería en un analizador de espectro. Una vez se obtiene esta gráfica, se mide la energía de todos los armónicos (en dB), se compara con el tono puro original y se calcula el porcentaje que representa del total. Cuanto mayor nivel tienen los armónicos, mayor es la distorsión armónica y peor "sonará" el equipo. Los fabricantes de equipos suelen facilitar este dato ya que es de los más relevantes.
La distorsión armónica o THD se mide en porcentaje (%) y los valores suelen ser siempre bastante inferiores al 1%. El porcentaje representa la parte del total de la energía a la salida, que pertenece a los armónicos, es decir, qué porcentaje es distorsión. Se calcula midiendo la tensión de las frecuencias armónicas y aplicando la siguiente fórmula:

Fórmula empleada para el cálculo de THD.
Donde V1, V2, V3... son las amplitudes en voltios de las distintas frecuencias armónicas y Vo es la amplitud del tono de frecuencia 1 KHz.
- Distorsión no Lineal IMD o Distorsión de Intermodulación:
Esta distorsión es debida a que varias frecuencias pertenecientes de una señal interactúan dentro del aparato generando unas terceras no deseadas. Uno de los métodos de medida es el siguiente: se introducen dos tonos puros (uno de 250 Hz y otro de 8 KHz y voltaje 1/4 del primero) y se mide el voltaje de las frecuencias de intermodulación a la salida. En la siguiente figura se representan las dos frecuencias puras y las posibles frecuencias de intermodulación (barras rojas).

Espectro de dos tonos puros (250Hz y 8kHz) y la distorsión armónica generada (rojo).
Las frecuencias resultantes de la intermodulación siempre aparecen en torno a la frecuencia más alta y separada de ella por múltiplos de la frecuencia más baja. En este caso las frecuencias de intermodulación aparecen en torno a la frecuencia de 8 KHz. y con distancias en frecuencia de 250 Hz, 500 Hz, 750 Hz... es decir a frecuencias 8K +/- n·250. Donde "n" toma valores de 1, 2, 3...
La distorsión de intermodulación se mide en porcentaje (%), y se calcularía midiendo la tensión de las frecuencias de intermodulación y aplicando la siguiente fórmula:

Fórmula empleada para el cálculo de IMD.
Donde Vi son las amplitudes en voltios de las distintas frecuencias de intermodulación y Vo es la amplitud del tono de frecuencia 8 KHz.
Relación Señal / Ruido:
La relación señal ruido (S/N) es la diferencia entre el nivel de la señal y el nivel de ruido. Se entiende como ruido cualquier señal no deseada, en este caso, la señal eléctrica no deseada que circula por el interior de un equipo electrónico. El ruido se mide sin ninguna señal a la entrada del equipo.
Se habla de relación señal ruido (S/N) porque el nivel de ruido es más o menos perjudicial en función de cual sea el nivel de la señal. La S /N se calcula como la diferencia entre el nivel de la señal cuando el aparato funciona a nivel nominal de trabajo y el nivel de ruido cuando, a ese mismo nivel de trabajo, no se introduce señal. En un amplificador, cuanto más se gire el mando de potencia, más se amplificará la señal y en la misma medida se amplificará el ruido.

Gráfica del nivel de la señal (verde) respecto al nivel de ruido (rojo).
A la salida de un equipo de audio, el nivel de la señal se mide en voltios (V). Midiendo en voltios la señal (S, signal), midiendo también en voltios el ruido (N, noise) y calculando el 20·log(S/N) se obtiene el valor de la relación señal ruido en dB, que es como normalmente se da. La calidad de un equipo se mide también por la relación señal ruido, cuanto mayor sea el valor de S/N mayor calidad tendrá el mismo.
La relación señal ruido se suele dar para una frecuencia de 1KHz. Aunque también se puede dar un valor para toda la banda de frecuencia de trabajo del aparato; en este caso se entiende que el valor de S/N es el menor para toda la banda, es decir, el más desfavorable. En el mejor de los casos se puede presentar la S /N como una gráfica del tipo respuesta en frecuencia, en donde se especifica el valor de la relación para cada una de las frecuencias.
La existencia ruido es inevitable en cualquier equipo electrónico. Una electrónica refinada disminuye el nivel de ruido, puede disminuirlo tanto que no sea medible por ser comparable al ruido del equipo de medida, pero siempre existe ruido. Algo parecido pasa con el sonido en el ambiente, es decir, por muchas condiciones de silencio que se den, siempre habrá ruido que será audible directamente o mediante métodos de amplificación. La fuente principal de ruido suele ser la fuente de alimentación del propio equipo.
Diafonía:
También se habla de "separación entre canales". Este efecto perjudicial se da únicamente en los equipos estéreo. Consiste en que la salida de un canal, se obtiene parte de la señal que está entrando al otro.
Debido a la cercanía de la electrónica que compone cada canal, las inducciones magnéticas y otros fenómenos magnetoeléctricos, si a la entrada del canal R de un equipo se introduce una señal, parte de esa señal también aparecerá a la salida del canal L, al que no se le introdujo ninguna. La diafonía suele aumentar conforme aumenta la frecuencia, a mayor frecuencia, menor separación entre canales. Este es un parámetro típico a tener en cuenta cuando se habla de amplificadores o etapas de potencia, ya que estos equipos manejan elevadas tensiones e intensidades que provocan fuertes inducciones. En el resto de equipos estéreo, la diafonía no suele alcanzar valores relevantes.
La diafonía o separación entre canales, se mide en dB (decibelios). Se suelen dar los valores (si se proporcionan) para unas frecuencias concretas significativas, típicamente 250 Hz, 1 KHz. y 10 KHz. También se suele especificar "diafonía inferior a "n" dB, lo que significa que para cada las frecuencias la separación entre canales es mayor o igual a "n" decibelios.
Bibliografía:
- Federico Miyara – Acústica y Sistemas de Sonido (1999) / CETEAR
- Ángel Rodríguez – La Dimensión Sonora
- Donald Fink – Manual de Audio (2006) / Mc Graw Hill
- Germán Suracce – Apuntes del Curso de Postproducción de Sonido del DCA
Hola soy andrea ronconi, disculpe que lo moleste pero necesitaba los apuntes porque en este momento no los puedo sacar, queria saber si habia alguna posibilidad que me los enviase en word. Mil gracias
ResponderEliminar